
Anomaliedetektion mit Methoden des maschinellen Lernens
Die effektive und zuverlässige Qualitätssicherung ist bei Schraubverbindungen aufgrund ihrer Häufigkeit besonders wichtig. Zur Qualitätssicherung gehört die Detektion von Anomalien zum frühestmöglichen Zeitpunkt, im besten Fall während der Montage. Um Fehlerquoten, Nacharbeits- oder Ausschusskosten sowie Reputationsschäden zu verringern, setzten viele Unternehmen bisher auf statistische Prozesskontrolle (SPC). Statistische Methoden zur Qualitätsüberwachung sind in der Regel mit hohem personellen Aufwand und hohem Zeitaufwand verbunden. Aus diesem Grund werden verschiedene maschinelle Lernverfahren zur Detektion von Anomalien in Schraubdaten analysiert. Allgemein soll dadurch die Notwendigkeit von menschlichen Inspektionen der Daten und der Anomalieerkennung minimiert werden sowie die Fehler mit höherer Genauigkeit, Konsistenz und Effizienz erkannt werden.
Grundlagen
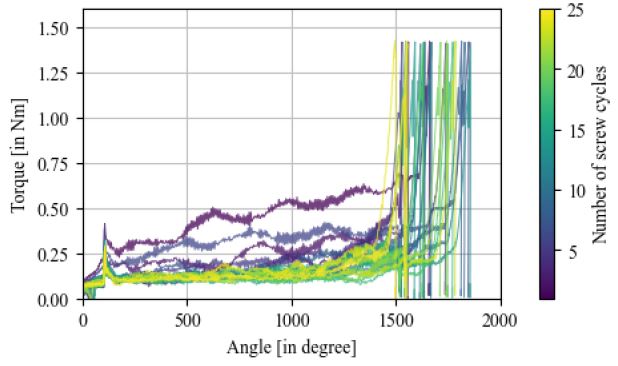
Mit einer automatisierten Schraubstation, die in der industriellen Fertigung eingesetzt wurde, werden jeweils zwei identische Verschraubungen zur Verbindung zweier Elemente eines Kunststoffgehäuses durchgeführt. Zu jeder Verschraubung wird unteranderem der Drehmoment-Drehwinkel-Verlauf aufgezeichnet. Außerdem erhält jede Verschraubung die Kennzeichnung OK bzw. NOK, die angibt, ob bestimmte Zielwerte für Drehmoment und -winkel erreicht wurden (OK) oder nicht (NOK). Aufgrund des besonders stabilen Fertigungsprozesses treten vergleichsweise selten Fehler auf, weshalb es sich um unausgeglichene Daten (Imbalanced Data) mit sehr vielen OK-Beobachtungen gegenüber sehr wenigen NOK-Beobachtungen handelt. Die Herausforderung und das Ziel ist es die Anomalien in den unterschiedlichen Drehmoment-Drehwinkel-Verläufen zu erkennen und die Verläufe nach ihren Fehlerbildern zu klassifizieren. An jedem Bauteil werden beide Verschraubungen 25-mal durchgeführt. In den Kunststoffbauteilen wird zuvor kein Gewinde geschnitten, weshalb mit jeder Verschraubung ein Gewinde in das gleiche Bauteil geschnitten wird.
Vorgehensweise/Methoden
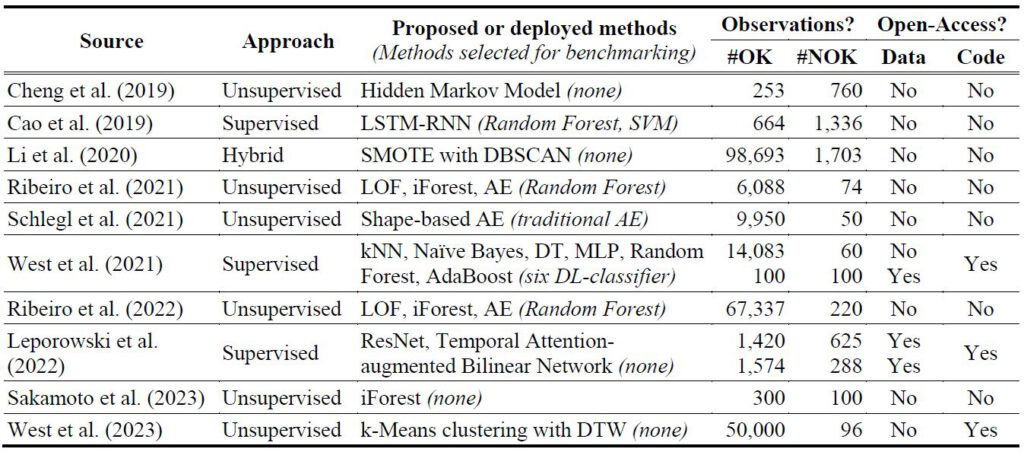
Das Ziel dieser Veröffentlichung ist das Potential von überwachten und unüberwachten Methoden des maschinellen Lernens zur Erkennung von Mustern anormaler Verschraubungen in Zeitreihen-Daten zu erforschen. Dazu werden zunächst verwandte Arbeiten zu diesem Themengebiet erläutert und in Tabellenform jeweils der Ansatz, die Methoden, die Anzahl an Beobachtungen aufgeteilt nach OK und NOK sowie die freie Verfügbarkeit des Datensatzes unterteilt nach Daten und Code, zusammengefasst.
Anschließend werden die acht Methoden zur Anomaliedetektion erläutert, die in dieser Veröffentlichung angewandt und dessen Ergebnisse analysiert werden. In den erhobenen Schraubdaten werden vier überwachte und vier unüberwachte Methoden verwendet.
Unüberwachte Methoden:
- Autoencoder
- DBSCAN
- Isolation Forest
- Local Outlier Factor
Überwachte Methoden:
- Random Forest
- Long Short-Term Memory
- Convolutional Neuronal Network
- Encoder
Zur Auswertung werden die folgenden Kennzahlen herangezogen:
- Accuracy
- Precision
- Recall
- Macro average F1 score
Zusammenfassung und Ausblick
In diesem Paper wurden acht verschiedene ML-Methoden auf einen real-world Datensatz angewandt und deren Ergebnisse analysiert. Random Forest erreicht die höchste Genauigkeit und den höchsten Macro average F1 score. Die LSTM-Methode hingegen zeigt eine große Variabilität und verdeutlicht die Bedeutung von Datenvorbereitung und Parameteranpassung. Die unüberwachten ML-Methoden konnten effizient bekannte und unerforschte Anomalien erkennen, wodurch z.B. die Qualität verbessert und Produktionskosten gesenkt werden können. Zukünftig werden für ausgewählte Methoden detailliertere Untersuchungen angestrebt sowie die Zugänglichkeit des Datensatzes vereinfacht und detaillierte Erläuterungen zur Datensammlung und dem Setup (Hardware, Software) veröffentlicht.
Die vollständige Veröffentlichung finden Sie unter diesem Link.