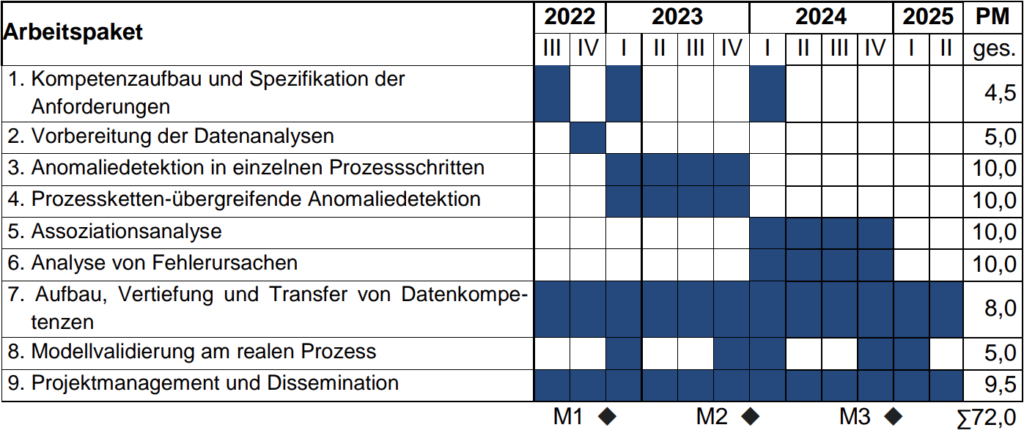
In diesem Jahresrückblick wird der aktuelle Stand des Forschungsprojekts mit den durchgeführten Arbeiten und Workshops und dessen Ergebnisse dargestellt, sowie ein kleiner Ausblick auf das Jahr 2024 gegeben. Das Forschungsprojekt umfasst die folgenden neun Arbeitspakete (AP) und dessen Zeitplan.
Zum Kompetenzaufbau wurde im Juli und November 2023 ein zweiteiliger Workshop namens „Grundlagen des Maschinellen Lernens“ beim IfW in Kassel durchgeführt. In diesem Workshop wurden zum einen die theoretischen Grundlagen des maschinellen Lernens und einiger überwachter sowie unüberwachter Lernmethoden vermittelt und zum anderen haben die Teilnehmenden nach einem Einstieg in die Datenanalysesoftware RapidMiner grundlegende Datenanalyseaufgaben gelöst, um mit der praktischen Umsetzung einen möglichst großen Lernerfolg zu erzielen. In dem November-Workshop wurde nach Wunsch der Teilnehmenden speziell die Anwendung von RapidMiner vertieft.
Im Folgenden ist die Anforderungsspezifikation zu den übergeordneten Analyseaufgaben zusammengefasst.

Das Arbeitspaket zur Vorbereitung der Datenanalysen wurde abgeschlossen. Es umfasst die Datenintegration und eine explorative Vorstudie. Um die in diesen Arbeiten verwendeten Zeitreihen vorzubereiten, müssen diese vollständig und äquidistant sein und eine einheitliche Länge haben. Diese Voraussetzung ist technisch nicht möglich. Deswegen wird dies durch datenwissenschaftliche Verfahren gelöst. Leerstellen in der Zeitreihe werden mithilfe von linerarer Regression interpoliert, Duplikate werden entfernt und durch geeignete Auffüllstrategien („padding strategies“) werden die Zeitreihen auf eine einheitliche Länge gebracht. Die Datenvorverarbeitungsschritte werden in einer eigenen Bibliothek vereinigt und nach der öffentlichen Bereitstellung der Daten publiziert. Außerdem erfolgten explorative Vorstudien der Schraub- und Spritzgussdaten. Es wurde eine Veröffentlichung über die Fähigkeit von unüberwachten, maschinellen Lernverfahren zur Erkennung von Anomalien in Schraubdaten erstellt. Darin wird das Clustering-Verfahren k-Means mit dem zeitreihenspezifischen Distanzmaß DTW (engl. für „dynamic time warping“) verknüpft. Mit einer Genauigkeit von 88.89% wurde im Anwendungsfall aus der Automobilindustrie ein gutes Ergebnis erzielt (weiterlesen). Die Schritte zur Analyse wurden öffentlich zugänglich gemacht (Link). Mit den Spritzgussdaten wurden ebenfalls unüberwachte Methoden erprobt. Hier wurde insbesondere eine visuelle Untersuchung nach einer Dimensionsreduktion mittels Hauptkomponentenanalyse durchgeführt. Außerdem wurde zur schnellen Visualisierung von einem oder mehreren Prozessverläufen ein Web-Werkzeug namens „H5-Viewer“ umgesetzt. Es ist auf die Datenstruktur der Spritzgussdaten voreingestellt und wurde mithilfe des Python-Framework streamlit umgesetzt und mit einer ausführlichen Dokumentation hier öffentlich zugänglich gemacht.
Es wurden erste Untersuchungen zur Anomaliedetektion in den einzelnen Prozessschritten gemacht. Dieses Arbeitspaket ist allerdings noch nicht abgeschlossen. Es wurden Pipelines zur Erprobung und zum Vergleich von verschiedenen Modellen erstellt. Zum Spritzgießprozess wurden zudem Kenntnisse zur Güte der Qualitätsdaten gewonnen. Aus Kennwerten, wie dem Bauteilgewicht, können gute Rückschlüsse auf Prozesseigenschaften gezogen werden. Geometrischen Angaben lassen hingegen keine verlässlichen und reproduzierbaren Aussagen zu. Beim Schraubprozess wurde neben der Erstellung einer Pipeline ein Benchmarking mit unterschiedlichen überwachten Ansätzen gemacht. Dies ermöglicht eine Referenz für die Analyse weiterer unüberwachter Ansätze. In der wissenschaftlichen Publikation zur HICSS 2024 werden vier überwachte und vier unüberwachte Ansätze verglichen. Die Ergebnisse einschließlich Dokumentation und Code, sowie ein Datensatz mit 5000 Verschraubungen wurden hier öffentlich bereitgestellt. Die Prozessketten-übergreifende Anomaliedetektion erfolgt im Anschluss an die Anomaliedetektion in den einzelnen Prozessschritten.
Zum Aufbau und Transfer von Datenkompetenzen wurde neben den Workshops zu den „Grundlagen des Maschinellen Lernens“ ein einwöchiger Python-Grundkurs entworfen, der sich an Ingenieure ohne explizite Vorerfahrung richtet. Er vermittelt Kenntnisse über die Syntax, das Einrichten von Entwicklungsumgebungen und den Einsatz von Versionsverwaltung. Darüber hinaus werden wichtige Bibliotheken zur Datenverwaltung, wie numpy und pandas, sowie zur Datenvisualisierung und -analyse, wie matplotlib und scikit-learn, behandelt. Der Python-Grundkurs wird im Frühjahr 2024 als Vorbereitung auf die Lehrveranstaltung „Industrial Data Science 2“ angeboten und durchgeführt.
Ausblick
Nach Abschluss der Anomaliedetektion in den einzelnen Prozessschritten und der Prozessketten-übergreifenden Anomaliedetektion erfolgt im Jahr 2024 neben einer Assoziationsanalyse die Analyse von Fehlerursachen. Außerdem wird der Python-Grundlagenkurs zum Aufbau und Transfer von Datenkompetenzen durchgeführt.
Schreibe einen Kommentar